O cerne da maioria dos algoritmos de aprendizado de máquina é o conceito de otimização, em que o objetivo é otimizar (minimizar ou maximizar) o valor de uma função objetivo em relação aos parâmetros dessa função. Em termos mais gerais, a Otimização Matemática pode ser descrita como a ciência de determinar as melhores soluções para problemas definidos matematicamente.
Formalmente, trata-se do processo de formulação e solução de um problema de otimização restrita da forma matemática geral:
$\underset{\text{w.r.t.}~\mathbf{x}}{\text{minimize }}f(\mathbf{x}), \mathbf{x} = [x_1, x_2,…,x_n]^T \in \mathbb{R}^n $
$\text{sujeito às restrições:} $
$g_j(\mathbf{x}) \leq 0, j = 1, 2, …, m $
$h_j(\mathbf{x}) = 0, j = 1, 2, …, r$
onde $f(\mathbf{x})$, $g_j(\mathbf{x})$ e $h_j(\mathbf{x})$ são funções escalares do vetor coluna real $\mathbf{x}$.
Os componentes contínuos $x_i$ de $\mathbf{x} = [x_1, x_2,…,x_n]^T$ são chamados de variáveis, $f(\mathbf{x})$ é a função objetivo, $g_j(\mathbf{x})$ representam as respectivas funções de restrição de desigualdade, e $h_j(\mathbf{x})$ as funções de restrição de igualdade. O vetor ótimo $\mathbf{x}$ que resolve o problema acima é denotado por $\mathbf{x^{\ast}}$, com o valor ótimo correspondente da função $f(\mathbf{x^{\ast}})$. Se nenhuma restrição for especificada, o problema é chamado de problema de minimização sem restrições.
Como exemplo, considere a minimização de uma função contínua e diferenciável $(C)$ de uma única variável real: $\text{minimize }f(x), x \in \mathbb{R}, f \in C$.
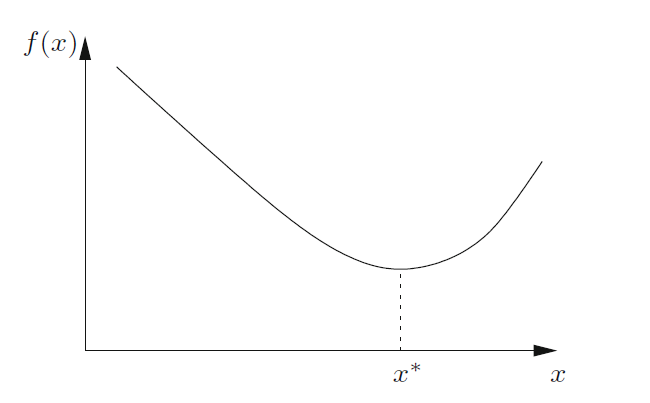
Para um mínimo local forte, é necessário determinar um $x^{\ast}$ tal que $f(x^{\ast}) < f(x)$ para todo $x$. Não é difícil, aos menos para os mais iniciados no assunto, perceber que $x^{\ast}$ ocorre onde a inclinação é zero, ou seja, onde: $\frac{df(x)}{dx} = 0$
Qual a relação entre otimização matemática e o Machine Learning?
Quase todos os algoritmos de aprendizado de máquina podem ser formulados como um problema de otimização para encontrar o extremo de uma função objetivo. A construção de modelos e a formulação de funções objetivo adequadas são o primeiro passo nos métodos de aprendizado de máquina. Com a função objetivo determinada, métodos de otimização apropriados são geralmente utilizados para resolver o problema de otimização.
A essência da maioria dos algoritmos de aprendizado de máquina é construir um modelo de otimização e ajustar os parâmetros da função objetivo a partir dos dados fornecidos.
Neste post, vamos considerar problemas de otimização no aprendizado supervisionado. Em outras palavras, o objetivo é encontrar uma função de mapeamento ótima $f(x)$ para minimizar a função de perda das amostras de treinamento:
$\underset{\theta}{\text{min }} \frac{1}{N}\sum_{i=0}^NL(y^i, f(x^i, \theta))$
onde $N$ é o número de amostras de treinamento, $\theta$ é o parâmetro da função de mapeamento, $x_i$ é o vetor de características da i-ésima amostra, $y_i$ é o rótulo correspondente, e $L$ é a função de perda.
Fazendo uso da informação do gradiente
Do ponto de vista das informações de gradiente em otimização, os métodos de otimização mais populares são: métodos de otimização de primeira ordem e de ordem superior. Muitos usuários prestam pouca atenção às características desses métodos, frequentemente os adotando como otimizadores de caixa preta. Em comparação com os métodos de otimização de primeira ordem, os métodos de ordem superior convergem em uma velocidade mais rápida, na qual a informação de curvatura torna a direção de busca mais eficaz.
No entanto, eles representam mais desafios. A dificuldade dos métodos de ordem superior reside na operação e no armazenamento da matriz inversa da matriz Hessiana. Por essa razão, o método de primeira ordem ainda é o mais utilizado.
No campo do aprendizado de máquina, os métodos de otimização de primeira ordem mais usados são baseados principalmente no gradiente descendente, que é um dos métodos mais populares para realizar otimização em algoritmos de machine learning.
Método do gradiente descendente
Conforme já apontado, o gradiente descendente é o método numérico mais utilizado na área da aprendizagem de máquina. A ideia do método de gradiente descendente é que os parâmetros sejam atualizados iterativamente na direção oposta aos gradientes da função objetivo, ou seja, o vetor gradiente de $L(y^i, f(x^i, \theta))$. A atualização é realizada para convergir gradualmente ao valor ótimo da função objetivo. A taxa de aprendizado $\eta$ determina o tamanho do passo em cada iteração e, portanto, influencia o número de iterações necessárias para alcançar o valor ótimo. Mas, o que é um vetor gradiente?
Considere uma função $f(\mathbf{x})$, para aqual existe, em qualquer ponto $\mathbf{x}$, um vetor de derivadas parciais de primeira ordem, chamado vetor gradiente:
$\nabla f = \begin{bmatrix}
\frac{\partial f(\mathbf{x})}{\partial x_1} \
\frac{\partial f(\mathbf{x})}{\partial x_2} \
\vdots \
\frac{\partial f(\mathbf{x})}{\partial x_n}
\end{bmatrix}$
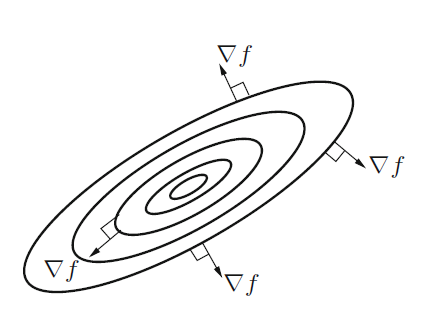
Note que, se a função $f(\mathbf{x})$ é contínua, então no ponto $\mathbf{x}$ o vetor gradiente $\nabla f$ é sempre perpendicular às curvas de nível (ou superfícies de valores constantes da função) e está na direção do aumento máximo de $f(\mathbf{x})$, conforme ilustrado na figura a seguir:
Variantes do Gradiente Descendente
Existem três variantes do gradiente descendente, que diferem na quantidade de dados que usamos para calcular o gradiente da função objetivo. Dependendo da quantidade de dados, fazemos um trade-off entre a precisão da atualização dos parâmetros e o tempo necessário para realizar uma atualização: Gradiente descendente em batch, Gradiente descendente estocástico, Gradiente descendente em mini-batch.
Gradiente Descendente em Batch
No Gradiente Descendente, a função de erro é definida em relação a um conjunto de treinamento, e, portanto, cada passo requer que o conjunto de treinamento inteiro seja processado para avaliar a função objetivo. As técnicas que usam o conjunto de dados completo de uma vez são chamadas de métodos em batch. O gradiente descendente em batch calcula o gradiente da função de custo em relação aos parâmetros $\theta$ para todo o conjunto de dados de treinamento, calculando os gradientes para todo o conjunto de dados para realizar apenas uma atualização. A equação abaixo descreve o gradiente descendente em batch:
$$
\theta = \theta – \eta*\nabla L(y, f(x, \theta))
$$
onde $\nabla L(y, f(x, \theta)) = \frac{\partial}{\partial\theta}L(y, f(x, \theta))$.
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params -learning_rate * params_gradPelas razões anteriormente descritas, o gradiente descendente em batch pode ser muito lento e se torna inviável para conjuntos de dados que não cabem na memória. Se o número de unidades amostrais é $N$ e a dimensão de $x$ é $D$, a complexidade de computação para cada iteração será $O(ND)$. Assim, o custo computacional torna-se inaceitável ao lidar com dados em grande escala. Como o gradiente descendente em batch tem alta complexidade computacional em cada iteração para dados em grande escala, o gradiente descendente estocástico (SGD) foi proposto.
Gradiente Descendente Estocástico
A ideia do gradiente descendente estocástico (SGD) é utilizar uma amostra aleatória para atualizar o gradiente a cada iteração, em vez de calcular diretamente o valor exato do gradiente. O custo desse método é independente do número de amostras e pode reduzir o tempo de atualização ao lidar com grandes quantidades de amostras, eliminando uma certa quantidade de redundância computacional, o que acelera significativamente o cálculo.
O SGD, em contraste com a versão em batch, realiza uma atualização de parâmetros para cada exemplo de treinamento $x^{(i)}$ e rótulo $y^{(i)}$:
$\theta = \theta – \eta*\nabla L(y^i, f(x^i, \theta))$
O gradiente descendente em batch realiza cálculos redundantes para grandes conjuntos de dados, uma vez que recalcula os gradientes para exemplos semelhantes antes de cada atualização de parâmetro. O SGD elimina essa redundância ao realizar uma atualização por vez.
Como o SGD utiliza apenas uma amostra por iteração, a complexidade de computação para cada iteração é $O(D)$, onde $D$ é o número de features. Quando o número de amostras $N$ é grande, a taxa de atualização para cada iteração do SGD é muito mais rápida do que a do gradiente descendente em batch.
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, \
example, params)
params = params -learning_rate * params_gradO vídeo abaixo simula o comportamento do gradiente descendente em batch em uma função multivariada
O SGD aumenta a eficiência geral da otimização à custa de mais iterações, mas o aumento no número de iterações é insignificante em comparação com a alta complexidade computacional causada por grandes quantidades de amostras. Portanto, em comparação com os métodos em batch, o SGD pode efetivamente reduzir a complexidade computacional e acelerar a convergência. Além disso, as oscilações do SGD, introduzidas pela seleção aleatória, permitem que ele salte para novos e potencialmente melhores mínimos locais.
Por outro lado, não se pode ganhar todas. Como a direção do gradiente oscila, isso pode levar ao problema da não convergência — já que o SGD tende a ultrapassar o ponto ótimo. Já foi observado que, ao diminuir lentamente a taxa de aprendizado, o SGD apresenta o mesmo comportamento de convergência que o gradiente descendente em batch. No entanto, algoritmos de otimização adicionais baseados na redução de variância foram propostos para melhorar a taxa de convergência.
E o Gradiente Descendente em mini-batch?
O gradiente descendente em mini-batch combina o melhor do GD e do SGD, realizando uma atualização para cada mini-batch considerando $n$ exemplos de treinamento:
$\theta = \theta – \eta*\nabla L(y^{(i:i+n)}, f(x^{(i:i+n)}, \theta))$
Dessa forma, ele a) reduz a variância das atualizações de parâmetros, o que pode levar a uma convergência mais estável; e b) pode fazer uso de otimizações matriciais altamente otimizadas comuns em bibliotecas de aprendizado profundo de última geração, tornando o cálculo do gradiente em relação a um mini-batch muito eficiente. Os tamanhos de mini-batch comuns variam entre 50 e 256, mas podem variar para diferentes aplicações. Ao usar GPUs com bastante VRAM, podemos experimentar tamanhos de batch muito maiores, sem medo de ser feliz :-).
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, \
batch, params)
params = params -learning_rate * params_gradCaso queira ver como esse processo funcionando na prática, nosso colaborador neste blog, Luís Gonçalves, disponibilizou este código aqui no github. O referido código considera o treinamento do algoritmo SVM, aplicando os conceitos vistos neste post, usando a biblioteca Numpy. O exemplo trata do problema de classificação binária, usando dados sintéticos, e minimizando a função de perda hinge:
$\text{max}(1 – y_i*(\mathbf{w}^T\mathbf{x}_i + b), 0)$.
A hinge loss penaliza predições incorretas ou de baixa confiança, sendo especialmente adequada para problemas de classificação binária.